The $3,000 Mystery: How Zombie Events Nearly Broke Our Budget
Last quarter, I was staring at our AWS bill with that familiar sinking feeling. Our event-driven architecture costs had somehow ballooned by $3,000 over six months, and nobody could figure out why.
When "Set It and Forget It" Goes Wrong
Event-driven architectures are supposed to make our lives easier. Decouple services, scale independently, handle traffic spikes gracefully—all the good stuff we read about in those Medium articles at 2 AM.
But here's what those articles don't tell you: events have a nasty habit of outliving their creators.
Remember that Black Friday promotion trigger you set up in November? Yeah, it's still running. That test subscription for the mobile app POC that got shelved? Still churning through events like it's 2019.
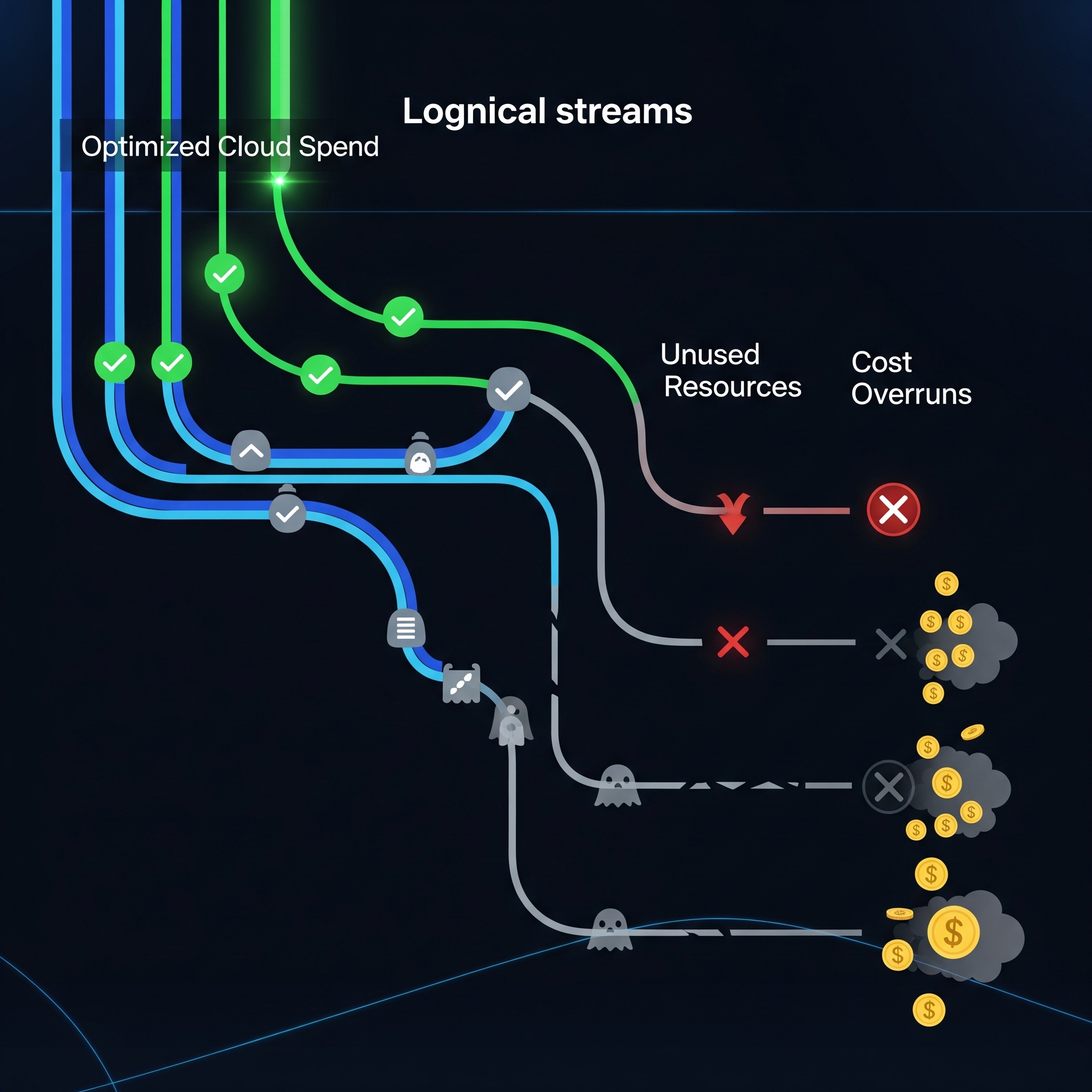
I call these "zombie events"—they're technically alive, consuming resources and generating costs, but they serve no living purpose.


The Great Event Audit of 2024
After three weeks of coffee-fueled debugging sessions and awkward Slack conversations with teammates about "that thing you built last year," we realized we needed a systematic approach.
The problem wasn't just the forgotten events. It was that we had no visibility into what was actually being used versus what was just... there.
Here's what we discovered during our audit:
- The Marketing Campaign Phantom: A trigger from a limited-time offer in Q2 was still firing daily, processing 50,000+ events for a campaign that ended months ago. Cost: ~$800/month.
- The Development Environment Ghost: Test subscriptions from a proof-of-concept were still active in production (yes, production), processing real customer events and storing them nowhere useful. Cost: ~$400/month.
- The Integration Zombie: An abandoned third-party integration was still subscribed to user events, failing silently on every attempt to forward data to a service that no longer existed. Cost: ~$200/month.
Each individually wasn't huge, but together? They were slowly bleeding our budget dry.
Building Our Zombie Detector
Rather than playing whack-a-mole with individual zombie events, we decided to build something smarter. Our approach was straightforward but effective:
- Event Flow Mapping
We created a real-time map of event flows, tracking which services actually consume events versus which ones are just subscribed. Think of it like a network topology, but for your event streams. - Activity Pattern Analysis
Not all quiet events are zombies. Some legitimate services have periodic or seasonal usage patterns. We built intelligence to distinguish between "genuinely unused" and "temporarily quiet." - Automated Health Checks
For each event subscription, we now validate that the consuming service is not only running but actually processing events successfully. Failed processors get flagged immediately. - Cost Attribution
Perhaps most importantly, we mapped every event flow to its actual cloud costs. Now when someone asks "what's this $500 charge for?" we can point to exactly which events are responsible.
The Results (And Why This Matters)
Within two weeks of implementing our zombie detection system:
- Immediate savings: $2,200/month in eliminated zombie costs
- Prevented incidents: Caught 3 failing integrations before they became customer-facing issues
- Improved performance: Reduced unnecessary event processing by 35%
- Better visibility: Our team finally understood what our event architecture actually looked like
But the real win wasn't the money—it was the peace of mind. No more mystery bills, no more "who owns this event?" conversations, no more wondering if that optimization actually worked.
Lessons Learned (The Hard Way)
- Documentation isn't enough: We had decent docs, but they quickly became outdated. Automated discovery beats manual documentation every time.
- Ownership matters: Every event trigger and subscription needs a clear owner. We now require team tags and auto-expire dates for all new event configurations.
- Monitor the monitors: Even our monitoring systems can accumulate technical debt. Regular audits aren't just for code—they're for infrastructure too.
What's Next?
We're not stopping here. The zombie detection system is now part of our standard deployment pipeline, and we're working on predictive cost modeling to catch potential zombies before they happen.
Event-driven architectures are powerful, but they require intentional maintenance. The good news? Once you have visibility into what's actually happening in your event flows, keeping them clean becomes much easier.
At EazyOps, we're building tools that help teams maintain this kind of architectural hygiene automatically. Because frankly, we'd all rather spend our time building features than hunting down rogue event subscriptions.
About Shujat
Shujat is a Senior Backend Engineer at EazyOps, working at the intersection of performance engineering, cloud cost optimization, and AI infrastructure. He writes to share practical strategies for building efficient, intelligent systems.